How to write a research data management plan#
About this guide#
This guide is for early stage postgraduate researcher (PGR), PhD, or students associated with the Henry Royce Institute and partners. We aim to guide you through a data management planning considerations, a general data management plan creation process and to point you to resources for support at the Henry Royce Institute and your Royce Partner Institution.
Data Management Planning#
A research data management plan (DMP) is a living document, i.e. continually edited, that outlines all the stages of your physical and digital research data lifecycle [1], illustrated in Fig. 1 [2]. A plan will include how the data will becollected, stored, protected, shared, and who will own the license rights to the data, before the data collection begins. Such plans can be updated at every point of the PhD research project lifetime, to reflect the data management needs of different studies.

Fig. 1 The research data lifecycle#
DMPs can be general across the project or outline how each study will be conducted. DMPs are a great way to outline your study and reflect on it, as they will highlight areas that require more attention, can evidence that your research is well planned, demonstrate to your industrial sponsor that you are implementing their data sharing and security policies in how you conduct your research, and are a self-made resource to aid thesis writing. Several awarding and funding bodies either recommend, or require dara management plans for awarding funding [3, 4, 5, 6].
During you research lifetime you might be tasked to write a DMP. Data management planning might appear daunting at first but is a skill that can be acquired and built on. Below you will find key considerations, resources and examples to begin data management planning. The table of contents on the right can help guide you to the content you are looking for, click on the resource title to be redirected to it through the page.
The research data lifecycle#
These online resources offer a detailed insight into the research data lifecycle:
Data life cycle, RDMkit, ELIXIR [2]
The Research Data Lifecycle - A Model for Data Management, The Turing Way [7]
Research Data Lifecycle, UK Data Service [1]
What is a research data management plan?#
Definition#
A data management plan is a living document that describes your project’s research data lifecycle. Research data has a longer lifespan than the project itself, and can be used, reused and adapted after the project ends, in other projects, internal or external to the originating research group. The data management lifecycle comprises the planning (project and data management), data collection process, data processing and analysis, management and storage during a research project. It also describes data ownership and how the data will be preserved and shared during and upon completion of a project [1, 2, 7, 8].
Reasons to write a Data Management Plan#
Writing a data management plan can be daunting as a new PhD student. You might not have done it before and being faced with a flush sheet of paper can lead to a block. When it comes to writing we always suggest that you should first get something down on paper. Once you have started, the process becomes easier. It is useful to approach the DMP as a tool to help you in your PGR project journey, rather than something preventing you from practicing research.
So, what are some reasons for devising and writing a DMP?
It is required by your university department, faculty, awarding body, funder, or a combination
It will help you be consistent with your data management
Being consistent with your data management means fast retrieval
Here are some other (selfish) reasons to write a DMP:
Writing a DMP can help highlight areas of your study that require a bit more attention
You can adapt a pre-existing DMP for a similar project
A DMP is a great resource to refer to when writing your thesis, it can even be adapted as written materials in your thesis, to describe the data collection process
Before you start#
Gather all your guidance and policy documents including:
Funder guidance
Funder approved DMP templates (https://rdmkit.elixir-europe.org/data_management_plan)
Institutional guidance
Private funder guidance (e.g. industrial sponsor)
What file-sharing policies does my industrial sponsor have in place?
What file security policies does my industrial sponsor require?
Will the data be commercially sensitive?
Who has first refusal on data ownership? (PhD contract)
Decide one your DMP workflow, and at what stages of your research to add to it. Your PhD might be one long project, supported by several smaller ones, or a long project with various stages of data collection. We recommend writing one DMP. The benefit of a living document is that you can always edit it.
Seek reviewers for your DMP. It is always a good idea to have your DMP reviewed by a diverse group of people, e.g. your supervisor/project PI, your group member, cohort PGR colleague, an institutional research services librarian (highly recommended!). They can help highlight inconsistencies, clear up confusion, and provide input. We all work with data, so getting people that don’t necessarily work in the same field as you, or are not researchers, can be very valuable
Consider yourself, your project, and your pre-existing resources
Pre-existing data
Digital
Is my PhD project a continuation from my Master’s Degree research project (self-generated data)?
Is my PhD project a continuation from a previous PhD student’s project or a Master’s student’s project (inherited data)?
Will I be using publicly available data, published alongside papers or in data repositories?
Physical
Will I receive samples?
Will I inherit samples?
Will I be creating samples out of raw materials?
Research group data management methods
Does my PI/Supervisor have a file-naming convention everyone adopts?
Does the group use a particular storage system?
How does my group share files internally and externally?
How does my group collaborate?
How does my group manage physical data storage, i.e. samples
Institutional data management resources, e.g. cloud storage providers (OneDrive, Google Drive, Dropbox Business, etc.), electronic laboratory notebooks, librarian or data curation services, data management plan writing software and reviewers, sample tracking software
Sensitive data
Consider the audience for your data management plan
Me, I am the intended audience for my data management plan
my supervisor
my colleagues
my awarding body (some awarding bodies might withhold progression unless you can supply a data management plan)
Important
Consulting funder, sponsor and institutional policy, and discussing with your supervisor who has first refusal to data ownership, will save you a lot of time
Data#
A data management plan outlines the research data lifecycle before the data is collected, as is applicable to each individual project. Not all these will apply to every individual project since all research projects are unique and have their own requirements.
The Turing Way Handbook defines data as
Data are objects that you use and produce during your research life cycle, encompassing datasets, software, code, workflow, models, figures, tables, images and videos, interviews, articles. Data are your research asset.
—The Turing Way Community
for materials science and engineering we might want to expand this definition, specifically when it comes to physical data, and include materials and samples as data.
Writing a research data management plan#
When to write a research data management plan#
Before starting a project
During the conception of a project
During the running of a project (not recommended)
After the project has finished (not recommended)
When to update a research data management plan#
If you migrated storage to a system not outlined in the latest version of your DMP
Before the start of a new cycle (sub-project) of your PhD project
When you have collected data and need to store or process it in such a way that is not covered by the latest iteration of your DMP
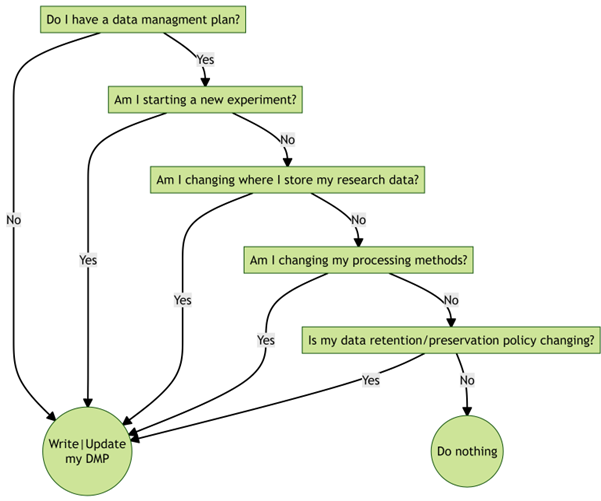
Fig. 2 When to write or update your data management plan#
Your research data lifecycle#
With the above in mind, we can delve into what might be included in each section of the planning of the research data lifecycle
Data collection#
Data collection should cover what data will be collected, or created, how it will be collected, and the file formats associated with the collected data.
Data can comprise
Physical data:
What physical data is going to be collected, including:
Samples from raw materials
Sample receipt and modification from industrial partners
How the physical data will be collected or created:
The equipment used to create the data
The physical size of the data (if applicable)
Digital data:
What digital data is going to be collected including:
generation of novel data from:
simulated data
data captured from measurement equipment
computer code, including software packages and analysis scripts
reuse of pre-existing in-group data
sourcing data from open (or closed sources)
How the digital data will be collected:
The equipment used to collect or create it
The file formats associated with the data, and whether they are proprietary
The volume of data including individual file size and the estimated amount generated
Data processing#
Data processing will usually involve what happens to the data after collection. Once data is collected it needs to pass by these processing stages to be ready for analysis in an order that suits one’s workflow.
Here are some considerations the data processing stage might involve:
Do I need to transfer the captured data to an area that is easily accessible to me for analysis
What is the most sensible file-naming convention I can follow for easily locating my data and fast retrieval?
Naming files in a sensible way that describes brief information about the data. Below is a general rule for file naming convention, leading to
2023-07-12_rdmp_guide_sd.md. However, we always suggest following your research groups file-naming convention if there is one in place:date of capture
what analysis generated the data
the initials of the person who captured the data
Do I need to convert my files to an open data format suitable for analysis, such as
.txt, or.csv?Do I need to clean the data for ingestion and convert data to a suitable data type?
This can include:
changing column names to a format compatible with your analysis programme, such as snake case or camel case
converting numbers which have been captured as text to integer or floating-point type
How should I document the organisation, conversion and cleaning process in a README file makes most sense to me and anyone wishing to use or reuse my data in the future?
Data Processing vs. Data Analysis
There might be some confusion over the distinction in data processing and analysis, as they usually will come together. A good way of thinking about it is that processing are all the steps required to prepare the data for, and facilitate analysis.
Data analysis#
Once the data is processed, cleaned and in a suitable location to be accessed by your analysis software it is time to analyse it. Usually, analysis is unique to each field, however, it is important to ensure that your analysis is reproducible by you or anyone wishing to reproduce the results so documentation of the analysis, either in a README file or the analysis script is important. This documentation of analysis will also aid in the writing of reports, journal articles, and the PhD thesis.
So, here are some considerations for writing your analysis README file:
If I wanted to repeat this analysis and get the same results in several months or years time, would I be able to with this README as a guide?
If someone other than myself wanted to repeat this analysis would they be able to understand the data and the analysis, and reproduce it?
Do I need someone to review this README to ensure the analysis is reproducible?
Documenting your project in DMPOnline
DMPOnline is one of our suggested tools for writing, updating, preserving and sharing your data management plan. The EPSRC approved tempate only has a small section on Documentation and Metadata. You can choose how brief or detailed you would like to be in describing your documentation process. However, we do suggest you have well-planned file organisation and documentation conventions set for your project for your future self, your supervisor, your group, and anyone building on from your work.
Data storage#
Data storage outlines how you will be storing the data following collection. Data storage will usually include an outline of how you will store the data, including:
preservation, archiving, retention
Storage:
Where the data will be stored
How the data will be backed up, including any data loss mitigation and duplicate data storage systems
How much storage space is required
Access:
Who has access to the data
How the approved users will access the data
Documentation and data quality
A file naming convention to adopt across all files for findability
How directories the data is kept in will be structured for findability
Metadata accompanying the data such as data dictionaries, README files
Documentation post-project for data archiving
Preservation, archiving and retention
Where and how the data will be stored after the end of the project
Whether the data will be reused
How long the data will be retained for
Data destruction plans This important as both physical and digital data take up physical space, so outlining how long the data will be retained for and any plans for reuse will help understand the long-term storage needs
Data protection#
Data protection can overlap with the access and data loss mitigation parts of ‘Data Storage’, and with ‘Data Sharing’. Data protection can expand to cover procedures for dealing with sensitive data, e.g. company data, redaction of sensitive information, embargo periods
Data ownership#
Data ownership covers intellectual property (IP) rights to the data. For fully government funded projects, IP rights usually belong to the institution where the research was primarily conducted. In certain cases, where part of the funding or resources come from private partners in industry, an agreement will dictate who has first refusal to IP rights. This can also cover terms under which sensitive data can be shared.
Data sharing#
Data sharing covers how you will be sharing your data internally, across collaborators, and externally. UK Research and Innovation (UKRI) funded research has a requirement for data to be shared openly, unless certain co-funder terms specify otherwise. As EPSRC funded research falls under UKRI, you might be required to share your data openly, unless an industrial partner wants the data to be kept confidential.
Data sharing will outline:
Data sharing procedures
Software to facilitate data sharing procedures
Who will be granted access to data sharing spaces
Whether web-apps such as Zendto or Privnote will be used to share data across:
collaborators at other institutions
industrial partners
Collaborations procedures across multi-institution projects
Open data sharing such as:
Depositing the data on open data repositories, such as Zenodo, Figshare, or institutional repositories
Transforming proprietary format data to an open format prior to release
Open access publishing plans in research journals
Code sharing, such as software, and data analysis and visualisation scripts on code repositories
Documentation describing the data such as:
README files
Data dictionaries
Package requirements for recreating coding environments
Metadata
A note about metadata
Metadata is as simple as data about your data, i.e. how it was captured, the process, who captured it and under what conditions. In the absence of metadata standards for your field, area of research, or measurement you can write a text file to accompany your dataset(s), explaining how it was captured and how it is presented, whether you are presenting, raw, cleaned, or cleaned and analysed data and how it’s tabulated
Example data management plans#
Below you will find some example DMPs where the authors elected to make them publicly available. These data management plans were generated using web applications built for the purpose of facilitating DMP writing. They implement custom DMP templates designed by institutes, or funders, and questions to help you consider each stage of your RDM lifecycle.
DMPonline#
DMPs produced using the DMPonline tool EPSRC template. The DMPonline tool is recommended by most Royce partners for UKRI (EPSRC, STFC) funded research projects. The DMPonline tool is developed by the Digital Curation Centre (DCC) and the University of California Curation Center (UC3).
DMPtool#
DMPs produced using the DMPtool. The DMPtool is developed by the University of California Curation Center and the Digital Curation Centre.
ORIENTATIONAL ORDER INDUCED BY A POLYMER NETWORK IN THE ISOTROPIC PHASE OF LIQUID CRYSTAL
Graphene and metal oxides composites: Application as toxic gas sensors
DMP tools
DMPonline and DMPtool are based on the same DMPRoadmap codebase
ARGOS - OpenAIRE Data Management Planning Tool#
DMPs from ARGOS can be downloaded and viewed by clicking export on the right-hand pane next to the DMP title and choosing your preferred export format.
Resources#
Royce partner institutional guidance#
Most Royce partners have a partnership with the DMP generation tool, DMPonline. Below we have compiled a non-exhaustive list of research data management and data management planning services provided at each Royce partner institution.
University of Cambridge#
The University of Cambridge runs its own Data Management Plan Support service, and suggests using the DCC DMPonline tool in its guidance.
Imperial College London#
Imperial College London has institutional guidance on how to complete a DMP on DCC DMPonline and runs a DMP consultation service for its researchers.
University of Leeds#
The University of Leeds Library hosts their own guidance on the University of Leeds website, runs its own support service through and has created a DMP template for its researchers available to download on their website.
University of Liverpool#
The University of Liverpool has developed their own Postgraduate Research student template, available via DMPOnline, it is an extensive template designed to guide you through every step of writing your data management plan.
DMPonline (Select the Liverpool template!)
The University of Manchester#
The University of Manchester has their own DMPonline service and excellent training and guidance by the University of Manchester Library hosted on their website.
University of Oxford#
Research Data Oxford runs as a cross-departmental service. They host their own guidance and have curated guidance from around the web on their website, and recommends DMPonline for DMP generation.
The University of Sheffield#
The University of Sheffield Library hosts their own research data management guidance and resources on their website and runs their own DMPonline service.
Further reading#
Here are some resources you might want to consult in addition to this guide.
Digital Training from The University of Manchester Library#
This training is available open and free online for anyone and not limited to PGR internal to the University of Manchester.
References#
- 1(1,2,3)
UK Data Service. Research data lifecycle. URL: https://www.youtube.com/watch?v=-wjFMMQD3UA.
- 2(1,2,3,4)
ELIXIR. Research data management kit. a deliverable from the eu-funded elixir-converge project (grant agreement 871075). URL: https://rdmkit.elixir-europe.org/.
- 3
Engineering & Physical Sciences Research Council, UK Research and Innovation. Policy framework on research data. principles of epsrc research data policy framework. URL: https://www.ukri.org/about-us/epsrc/our-policies-and-standards/policy-framework-on-research-data/principles/.
- 4
Science and Technology Facilities Council, UK Research and Innovation. Stfc scientific data policy. URL: https://www.ukri.org/publications/stfc-scientific-data-policy/.
- 5
Science and Technology Facilities Council, UK Research and Innovation. Data management plan. URL: https://www.ukri.org/councils/stfc/guidance-for-applicants/what-to-include-in-your-proposal/data-management-plan/.
- 6
UK Research and Innovation. Publishing your research findings. making your research data open. URL: https://www.ukri.org/manage-your-award/publishing-your-research-findings/making-your-research-data-open/.
- 7(1,2)
The Turing Way Community. The turing way: a handbook for reproducible, ethical and collaborative research. doi:10.5281/zenodo.3233853.
- 8
Madeleine Pownall, Flávio Azevedo, Laura M. König, Hannah R. Slack, Thomas Rhys Evans, Zoe Flack, Sandra Grinschgl, Mahmoud M. Elsherif, Katie A. Gilligan-Lee, Catia M. F. de Oliveira, Biljana Gjoneska, Tamara Kalandadze, Katherine Button, Sarah Ashcroft-Jones, Jenny Terry, Nihan Albayrak-Aydemir, Filip Děchtěrenko, Shilaan Alzahawi, Bradley J. Baker, Merle-Marie Pittelkow, Lydia Riedl, Kathleen Schmidt, Charlotte R. Pennington, John J. Shaw, Timo Lüke, Matthew C. Makel, Helena Hartmann, Mirela Zaneva, Daniel Walker, Steven Verheyen, Daniel Cox, Jennifer Mattschey, Tom Gallagher-Mitchell, Peter Branney, Yanna Weisberg, Kamil Izydorczak, Ali H. Al-Hoorie, Ann-Marie Creaven, Suzanne L. K. Stewart, Kai Krautter, Karen Matvienko-Sikar, Samuel J. Westwood, Patr\'ıcia Arriaga, Meng Liu, Myriam A. Baum, Tobias Wingen, Robert M. Ross, Aoife O\textquotesingle Mahony, Agata Bochynska, Michelle Jamieson, Myrthe Vel Tromp, Siu Kit Yeung, Martin R. Vasilev, Amélie Gourdon-Kanhukamwe, Leticia Micheli, Markus Konkol, David Moreau, James E. Bartlett, Kait Clark, Gwen Brekelmans, Theofilos Gkinopoulos, Samantha L. Tyler, Jan Philipp Röer, Zlatomira G. Ilchovska, Christopher R. Madan, Olly Robertson, Bethan J. Iley, Samuel Guay, Martina Sladekova, and Shanu Sadhwani. Teaching open and reproducible scholarship: a critical review of the evidence base for current pedagogical methods and their outcomes. Royal Society Open Science, 2023. doi:https://doi.org/10.1098/rsos.221255.
- 9
Anja Perry. Data management plans and data management costs. doi:10.5281/zenodo.7759355.
- 10
OpenAIRE. Raw data, backup and versioning. URL: https://www.openaire.eu/RAW-DATA-BACKUP-AND-VERSIONING.
- 11
OpenAIRE. Guides for researchers: how to deal with non-digital data. URL: https://www.openaire.eu/non-digital-data-guide.
- 12
OpenAIRE. Data formats for preservation. URL: https://www.openaire.eu/data-formats-preservation-guide.
- 13
S Jones. How to develop a data management and sharing plan. dcc how-to guides. URL: https://www.dcc.ac.uk/guidance/how-guides/develop-data-plan.